| Record Information |
|---|
| Version | 5.0 |
|---|
| Status | Detected but not Quantified |
|---|
| Creation Date | 2006-08-12 19:12:38 UTC |
|---|
| Update Date | 2022-09-22 18:34:17 UTC |
|---|
| HMDB ID | HMDB0003349 |
|---|
| Secondary Accession Numbers | |
|---|
| Metabolite Identification |
|---|
| Common Name | L-Dihydroorotic acid |
|---|
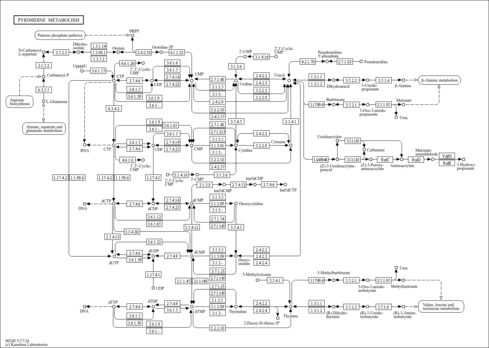
| Description | L-Dihydroorotic acid, also known as (S)-4,5-dihydroorotate or dihydro-L-orotate, belongs to the class of organic compounds known as alpha amino acids and derivatives. These are amino acids in which the amino group is attached to the carbon atom immediately adjacent to the carboxylate group (alpha carbon), or a derivative thereof. 4,5-Dihydroorotic acid is a derivative of orotic acid which serves as an intermediate in pyrimidine biosynthesis. L-Dihydroorotic acid is a drug. L-Dihydroorotic acid exists in all living species, ranging from bacteria to humans. Within humans, L-dihydroorotic acid participates in a number of enzymatic reactions. In particular, L-dihydroorotic acid can be biosynthesized from ureidosuccinic acid; which is catalyzed by the enzyme cad protein. In addition, L-dihydroorotic acid and quinone can be converted into orotic acid through the action of the enzyme dihydroorotate dehydrogenase (quinone), mitochondrial. In humans, L-dihydroorotic acid is involved in the metabolic disorder called the beta-ureidopropionase deficiency pathway. Outside of the human body, L-dihydroorotic acid has been detected, but not quantified in several different foods, such as black chokeberries, vanilla, sweet basils, soy beans, and broad beans. |
|---|
| Structure | OC(=O)[C@@H]1CC(=O)NC(=O)N1 InChI=1S/C5H6N2O4/c8-3-1-2(4(9)10)6-5(11)7-3/h2H,1H2,(H,9,10)(H2,6,7,8,11)/t2-/m0/s1 |
|---|
| Synonyms | | Value | Source |
|---|
| (S)-4,5-Dihydroorotic acid | ChEBI | | Dihydro-L-orotic acid | ChEBI | | (S)-4,5-Dihydroorotate | Kegg | | L-Dihydroorotate | Kegg | | Dihydro-L-orotate | Generator | | (S)-Dihydroorotate | HMDB | | 4,5-Dihydroorotic acid, (L)-isomer | HMDB | | 5,6-Dihydroorotate | HMDB | | 4,5-Dihydroorotic acid | HMDB | | 4,5-Dihydroorotic acid, (DL)-isomer | HMDB | | Dihydroorotate | HMDB | | Hydroorotic acid | HMDB | | 4,5-Dihydroorotic acid, (D)-isomer | HMDB |
|
|---|
| Chemical Formula | C5H6N2O4 |
|---|
| Average Molecular Weight | 158.1121 |
|---|
| Monoisotopic Molecular Weight | 158.03275669 |
|---|
| IUPAC Name | (4S)-2,6-dioxo-1,3-diazinane-4-carboxylic acid |
|---|
| Traditional Name | L-dihydroorotic acid |
|---|
| CAS Registry Number | 5988-19-2 |
|---|
| SMILES | OC(=O)[C@@H]1CC(=O)NC(=O)N1 |
|---|
| InChI Identifier | InChI=1S/C5H6N2O4/c8-3-1-2(4(9)10)6-5(11)7-3/h2H,1H2,(H,9,10)(H2,6,7,8,11)/t2-/m0/s1 |
|---|
| InChI Key | UFIVEPVSAGBUSI-REOHCLBHSA-N |
|---|
| Chemical Taxonomy |
|---|
| Description | Belongs to the class of organic compounds known as alpha amino acids and derivatives. These are amino acids in which the amino group is attached to the carbon atom immediately adjacent to the carboxylate group (alpha carbon), or a derivative thereof. |
|---|
| Kingdom | Organic compounds |
|---|
| Super Class | Organic acids and derivatives |
|---|
| Class | Carboxylic acids and derivatives |
|---|
| Sub Class | Amino acids, peptides, and analogues |
|---|
| Direct Parent | Alpha amino acids and derivatives |
|---|
| Alternative Parents | |
|---|
| Substituents | - Alpha-amino acid or derivatives
- N-acyl urea
- Pyrimidone
- Ureide
- 1,3-diazinane
- Pyrimidine
- Dicarboximide
- Urea
- Carbonic acid derivative
- Azacycle
- Monocarboxylic acid or derivatives
- Carboxylic acid
- Organoheterocyclic compound
- Hydrocarbon derivative
- Organic oxide
- Organooxygen compound
- Organonitrogen compound
- Organopnictogen compound
- Organic oxygen compound
- Carbonyl group
- Organic nitrogen compound
- Aliphatic heteromonocyclic compound
|
|---|
| Molecular Framework | Aliphatic heteromonocyclic compounds |
|---|
| External Descriptors | |
|---|
| Ontology |
|---|
| Physiological effect | Not Available |
|---|
| Disposition | |
|---|
| Process | |
|---|
| Role | |
|---|
| Physical Properties |
|---|
| State | Solid |
|---|
| Experimental Molecular Properties | | Property | Value | Reference |
|---|
| Melting Point | Not Available | Not Available | | Boiling Point | Not Available | Not Available | | Water Solubility | Not Available | Not Available | | LogP | Not Available | Not Available |
|
|---|
| Experimental Chromatographic Properties | Experimental Collision Cross Sections |
|---|
| Predicted Molecular Properties | |
|---|
| Predicted Chromatographic Properties | Predicted Collision Cross SectionsPredicted Kovats Retention IndicesUnderivatizedDerivatized| Derivative Name / Structure | SMILES | Kovats RI Value | Column Type | Reference |
|---|
| L-Dihydroorotic acid,1TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1 | 1639.6 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,1TMS,isomer #2 | C[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)NC1=O | 1677.1 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,1TMS,isomer #3 | C[Si](C)(C)N1C(=O)NC(=O)C[C@H]1C(=O)O | 1654.6 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1 | 1693.9 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1 | 1815.5 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1 | 2895.1 | Standard polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #2 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C | 1676.2 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #2 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C | 1820.3 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #2 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C | 3092.7 | Standard polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #3 | C[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C)C1=O | 1640.2 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #3 | C[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C)C1=O | 1744.7 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TMS,isomer #3 | C[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C)C1=O | 2525.0 | Standard polar | 33892256 | | L-Dihydroorotic acid,3TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1[Si](C)(C)C | 1672.0 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,3TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1[Si](C)(C)C | 1797.3 | Standard non polar | 33892256 | | L-Dihydroorotic acid,3TMS,isomer #1 | C[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C)C(=O)N1[Si](C)(C)C | 2213.1 | Standard polar | 33892256 | | L-Dihydroorotic acid,1TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1 | 1894.0 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,1TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)NC1=O | 1969.3 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,1TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N1C(=O)NC(=O)C[C@H]1C(=O)O | 1951.1 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1 | 2153.6 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1 | 2258.8 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1 | 2839.9 | Standard polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C(C)(C)C | 2149.1 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C(C)(C)C | 2281.6 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)NC(=O)N1[Si](C)(C)C(C)(C)C | 3001.0 | Standard polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C(C)(C)C)C1=O | 2135.0 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C(C)(C)C)C1=O | 2215.5 | Standard non polar | 33892256 | | L-Dihydroorotic acid,2TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N1C(=O)C[C@@H](C(=O)O)N([Si](C)(C)C(C)(C)C)C1=O | 2535.7 | Standard polar | 33892256 | | L-Dihydroorotic acid,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1[Si](C)(C)C(C)(C)C | 2336.9 | Semi standard non polar | 33892256 | | L-Dihydroorotic acid,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1[Si](C)(C)C(C)(C)C | 2469.1 | Standard non polar | 33892256 | | L-Dihydroorotic acid,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)OC(=O)[C@@H]1CC(=O)N([Si](C)(C)C(C)(C)C)C(=O)N1[Si](C)(C)C(C)(C)C | 2459.7 | Standard polar | 33892256 |
|
|---|
| GC-MS Spectra| Spectrum Type | Description | Splash Key | Deposition Date | Source | View |
|---|
| Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-EI-TOF (Pegasus III TOF-MS system, Leco; GC 6890, Agilent Technologies) (Non-derivatized) | splash10-0zfs-1920000000-6e853bcb65fafce1f25e | 2014-06-16 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-EI-TOF (Pegasus III TOF-MS system, Leco; GC 6890, Agilent Technologies) (Non-derivatized) | splash10-000j-1900000000-4c364adc386eb5db027b | 2014-06-16 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-EI-TOF (Pegasus III TOF-MS system, Leco; GC 6890, Agilent Technologies) (Non-derivatized) | splash10-0zfs-0930000000-373786ac89c19f0cbc6b | 2014-06-16 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-MS (3 TMS) | splash10-0pb9-2951000000-9975cf569acb6854865d | 2014-06-16 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-MS (4 TMS) | splash10-005a-5938000000-6f622577780cd53385eb | 2014-06-16 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-EI-TOF (Non-derivatized) | splash10-0zfs-1920000000-6e853bcb65fafce1f25e | 2017-09-12 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-MS (Non-derivatized) | splash10-0pb9-2951000000-9975cf569acb6854865d | 2017-09-12 | HMDB team, MONA, MassBank | View Spectrum | | Experimental GC-MS | GC-MS Spectrum - L-Dihydroorotic acid GC-MS (Non-derivatized) | splash10-005a-5938000000-6f622577780cd53385eb | 2017-09-12 | HMDB team, MONA, MassBank | View Spectrum | | Predicted GC-MS | Predicted GC-MS Spectrum - L-Dihydroorotic acid GC-MS (Non-derivatized) - 70eV, Positive | splash10-000f-9400000000-248b8d6d703ba73c2058 | 2016-09-22 | Wishart Lab | View Spectrum | | Predicted GC-MS | Predicted GC-MS Spectrum - L-Dihydroorotic acid GC-MS (1 TMS) - 70eV, Positive | splash10-03di-3900000000-b0776f22820e6e570a09 | 2017-10-06 | Wishart Lab | View Spectrum | | Predicted GC-MS | Predicted GC-MS Spectrum - L-Dihydroorotic acid GC-MS (Non-derivatized) - 70eV, Positive | Not Available | 2021-10-12 | Wishart Lab | View Spectrum |
MS/MS Spectra| Spectrum Type | Description | Splash Key | Deposition Date | Source | View |
|---|
| Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid Quattro_QQQ 10V, Positive-QTOF (Annotated) | splash10-059i-9700000000-681989bb70419ccf0e26 | 2012-07-25 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid Quattro_QQQ 25V, Positive-QTOF (Annotated) | splash10-00di-9000000000-c08746cfe4c476aff942 | 2012-07-25 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid Quattro_QQQ 40V, Positive-QTOF (Annotated) | splash10-006x-9000000000-c59db6f9b23380c30e8c | 2012-07-25 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid , negative-QTOF | splash10-001i-2920000000-1c8b06ed77517a0e8606 | 2017-09-14 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid , positive-QTOF | splash10-03k9-4900000000-5b6e94f06ce0c97ad751 | 2017-09-14 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Negative-QTOF | splash10-03dl-9800000000-933d1487bcb4d23e2a5a | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 35V, Negative-QTOF | splash10-0006-9000000000-34d46a3aa973f0412a45 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Positive-QTOF | splash10-00di-9100000000-0004fe5f5bbd6b1f1a41 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Positive-QTOF | splash10-05fr-9000000000-9accaaec3ae3b41f55a9 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Positive-QTOF | splash10-00di-9000000000-41686c36ddb271856b65 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Positive-QTOF | splash10-074u-9500000000-c4e4ed6470c8ad78afec | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Positive-QTOF | splash10-0006-9000000000-8214c2f0d9df1ac7c79c | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Positive-QTOF | splash10-022i-9400000000-257f9838bad9d558822c | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Negative-QTOF | splash10-0006-9000000000-2e8bea71938b0c3ee548 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Experimental LC-MS/MS | LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Negative-QTOF | splash10-0006-9100000000-8cda59dcc275524136f4 | 2021-09-20 | HMDB team, MONA | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Positive-QTOF | splash10-0a4i-0900000000-2ddb498acc970a567f6b | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Positive-QTOF | splash10-03dl-5900000000-4b73ae512e57466dd4e6 | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Positive-QTOF | splash10-0006-9100000000-d6c31a36d6fe5c68d9e1 | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Negative-QTOF | splash10-0a4i-1900000000-c84801951eaa1da750f7 | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Negative-QTOF | splash10-0006-9000000000-4ae1d11ab20f903606c3 | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Negative-QTOF | splash10-0006-9000000000-aec3a40befb20e60f21b | 2016-09-12 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Negative-QTOF | splash10-0a4i-0900000000-b0c5e687f246809cdae9 | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 20V, Negative-QTOF | splash10-01ox-6900000000-cb60b796898e6ca4336d | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 40V, Negative-QTOF | splash10-0006-9000000000-fccf5d7216b23cffed7a | 2021-09-22 | Wishart Lab | View Spectrum | | Predicted LC-MS/MS | Predicted LC-MS/MS Spectrum - L-Dihydroorotic acid 10V, Positive-QTOF | splash10-06r6-0900000000-86736ae769db7bc83c23 | 2021-09-22 | Wishart Lab | View Spectrum |
NMR Spectra| Spectrum Type | Description | Deposition Date | Source | View |
|---|
| Experimental 1D NMR | 1H NMR Spectrum (1D, 600 MHz, H2O, experimental) | 2012-12-05 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 100 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 100 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 1000 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 1000 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 200 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 200 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 300 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 300 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 400 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 400 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 500 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 500 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 600 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 600 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 700 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 700 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 800 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 800 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 1H NMR Spectrum (1D, 900 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Predicted 1D NMR | 13C NMR Spectrum (1D, 900 MHz, D2O, predicted) | 2021-09-25 | Wishart Lab | View Spectrum | | Experimental 2D NMR | [1H, 13C]-HSQC NMR Spectrum (2D, 600 MHz, H2O, experimental) | 2012-12-05 | Wishart Lab | View Spectrum |
|
|---|


{kind=link}