| Derivative Name / Structure | SMILES | Kovats RI Value | Column Type | Reference |
|---|
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 2743.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #2 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O)O)[C@H]1O | 2754.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #3 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](NC(=N)CNC=O)[C@H](O)[C@@H]1O | 2828.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #4 | C[Si](C)(C)N(C(=N)CNC=O)[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2788.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #5 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2718.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TMS,isomer #6 | C[Si](C)(C)N(C=O)CC(=N)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2901.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 2721.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #10 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CNC=O)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2842.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #11 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@H](O)[C@@H]1O | 2813.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #12 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2753.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #13 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@H](O)[C@@H]1O | 2928.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #14 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2721.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #15 | C[Si](C)(C)N(C=O)CC(=N)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2835.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #16 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2813.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 2794.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #3 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 2732.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #4 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O | 2693.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 2835.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #6 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@H]1O | 2805.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #7 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 2741.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #8 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C | 2690.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TMS,isomer #9 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O)O)[C@H]1O | 2845.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 2750.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 2521.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 4332.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2778.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2769.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 4611.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O | 2786.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O | 2729.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O | 4651.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #12 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 2799.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #12 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 2564.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #12 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 4076.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 2757.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 2641.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 4240.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #14 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2724.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #14 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2565.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #14 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 4310.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #15 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@H]1O | 2867.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #15 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@H]1O | 2635.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #15 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@H]1O | 4307.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2693.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2708.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 4516.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #17 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2791.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #17 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2770.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #17 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 4635.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #18 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C | 2787.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #18 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C | 2740.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #18 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C | 4654.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #19 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2808.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #19 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2664.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #19 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 4033.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2702.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2626.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 4586.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #20 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2752.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #20 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2575.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #20 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 4106.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #21 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2899.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #21 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2677.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #21 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 4042.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2745.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2660.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 4213.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #23 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O | 2854.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #23 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O | 2766.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #23 | C[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O | 4321.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2853.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2673.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 4351.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2775.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2856.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C | 4594.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2647.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2601.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 4676.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2784.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2621.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 4679.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 2792.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 2559.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 3987.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 2749.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 2639.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 4212.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #7 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2719.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #7 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2557.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #7 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 4296.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 2865.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 2626.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 4235.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2688.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2697.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 4500.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 2763.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 2531.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C | 3830.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 2836.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 2612.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #10 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O | 3740.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #11 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2735.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #11 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2599.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #11 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 3849.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #12 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2804.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #12 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2717.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #12 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 3976.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #13 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2812.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #13 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2614.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #13 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 4056.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2750.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2772.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 4192.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #15 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 2794.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #15 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 2631.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #15 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C | 3711.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2759.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2537.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #16 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 3834.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #17 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 2839.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #17 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 2624.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #17 | C[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@H]1O | 3841.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #18 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2730.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #18 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2616.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #18 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3870.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #19 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2809.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #19 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2723.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #19 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 4004.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2742.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2618.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 3923.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #20 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2811.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #20 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2627.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #20 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 4073.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #21 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2748.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #21 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2788.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #21 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 4198.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2776.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2607.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #22 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 3697.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #23 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2840.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #23 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 2735.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #23 | C[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C | 3815.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2823.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 2631.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #24 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O | 3875.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2804.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2714.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #25 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 3969.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2717.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2530.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #3 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 4076.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2795.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2601.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #4 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 4080.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #5 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2662.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #5 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2662.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #5 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 4139.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2747.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2726.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #6 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 4287.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2743.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2676.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 4375.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 2790.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 2625.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #8 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O | 3668.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2764.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2526.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TMS,isomer #9 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 3795.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2774.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2602.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #1 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 3444.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #10 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2811.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #10 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 2583.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #10 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O | 3599.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2798.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2669.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #11 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 3647.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #12 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2754.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #12 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2575.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #12 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3417.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2821.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 2693.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #13 | C[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C | 3564.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2804.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 2605.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #14 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C | 3634.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #15 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2789.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #15 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2688.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #15 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3656.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #16 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2836.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #16 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 2670.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #16 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C | 3530.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #2 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2754.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #2 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2501.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #2 | C[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 3606.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #3 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2791.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #3 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2586.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #3 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 3636.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #4 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2712.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #4 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2581.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #4 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3576.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2774.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2698.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #5 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 3736.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2777.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2598.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 3836.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2719.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2744.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #7 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3853.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #8 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2762.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #8 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2551.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #8 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 3386.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #9 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2812.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #9 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 2683.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TMS,isomer #9 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O | 3525.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #1 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2747.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #1 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2559.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #1 | C[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3197.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2810.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 2682.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #2 | C[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C)[Si](C)(C)C)[C@@H]1O[Si](C)(C)C | 3352.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #3 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2792.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #3 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 2572.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #3 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C | 3446.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #4 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2760.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #4 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2662.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #4 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3425.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #5 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2811.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #5 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 2618.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #5 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O)[Si](C)(C)C | 3280.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2802.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2645.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,6TMS,isomer #6 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3299.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,7TMS,isomer #1 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2804.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,7TMS,isomer #1 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 2645.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,7TMS,isomer #1 | C[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C)O[Si](C)(C)C)[C@@H](O[Si](C)(C)C)[C@H]1O[Si](C)(C)C)[Si](C)(C)C | 3129.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 2976.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O)O)[C@H]1O | 2984.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](NC(=N)CNC=O)[C@H](O)[C@@H]1O | 3066.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)N(C(=N)CNC=O)[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2982.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 2949.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,1TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)N(C=O)CC(=N)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 3088.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3123.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CNC=O)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3278.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O | 3231.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3197.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O | 3337.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3129.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)N(C=O)CC(=N)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3216.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O | 3218.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 3225.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3120.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3085.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3234.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3244.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3122.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3091.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,2TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O)O)[C@H]1O | 3248.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3398.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3090.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 4321.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3373.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3298.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 4512.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3372.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3251.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 4555.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3443.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3087.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CNC=O)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 4137.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3390.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3174.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 4217.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3360.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3081.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 4278.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3490.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3198.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@H]1O | 4332.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3300.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3213.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 4390.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3381.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3303.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 4532.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3378.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3257.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 4564.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3447.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3160.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 4073.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3309.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3183.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 4459.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3400.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3052.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 4125.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3512.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3191.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 4129.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3374.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3153.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 4193.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O | 3458.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O | 3281.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(O)OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O | 4314.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3449.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3195.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 4350.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3390.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3337.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 4499.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3267.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3116.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 4534.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3395.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3208.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 4595.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 3440.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 3086.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O | 4048.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3393.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3170.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 4191.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3365.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3077.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 4256.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3478.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3194.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 4260.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3299.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3200.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,3TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 4378.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3595.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3196.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CNC=O)[C@@H]1O[Si](C)(C)C(C)(C)C | 3931.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3656.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3292.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3872.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3543.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3240.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3892.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3625.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3399.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 4004.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3606.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3289.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 4065.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3560.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3427.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 4160.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3609.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3269.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C | 3823.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3564.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3146.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3904.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3663.6 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3299.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #17 | CC(C)(C)[Si](C)(C)O[C@H]1[C@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@H]1O | 3963.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3537.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3257.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #18 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3904.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3625.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3400.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #19 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 4026.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3560.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3294.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3935.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3606.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3305.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #20 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 4083.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3562.1 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3441.8 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #21 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 4163.5 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3575.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3202.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #22 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3823.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3654.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3377.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #23 | CC(C)(C)[Si](C)(C)OP(=O)(OC[C@H]1O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@H](O)[C@@H]1O)O[Si](C)(C)C(C)(C)C | 3930.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3618.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3272.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #24 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O | 3980.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3604.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3372.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #25 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 4038.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3523.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3174.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 4043.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3638.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3316.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 4104.1 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3476.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3313.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 4067.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3562.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3423.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 4199.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3547.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3348.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 4281.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3612.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3267.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3785.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3568.4 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3131.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,4TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3864.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3760.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3385.7 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #1 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CNC=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3675.8 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3783.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3354.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #10 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O | 3787.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3781.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3467.6 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #11 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3824.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3738.0 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3302.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #12 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3659.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3817.3 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3489.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #13 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@H](O)[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@H]1N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3767.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3787.8 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3374.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #14 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C | 3817.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3777.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3486.3 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #15 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3828.4 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3794.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3425.2 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #16 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O)[C@H]1O)[Si](C)(C)C(C)(C)C | 3769.0 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3715.5 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3232.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #2 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N[C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3767.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3802.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3414.5 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #3 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](NC(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3834.2 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3722.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3356.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #4 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3739.6 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3794.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3532.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #5 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O[Si](C)(C)C(C)(C)C | 3850.7 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3756.7 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3402.4 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #6 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N[C@@H]1O[C@H](COP(=O)(O)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C | 3920.9 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3750.2 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3542.1 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #7 | CC(C)(C)[Si](C)(C)N=C(CN(C=O)[Si](C)(C)C(C)(C)C)N([C@@H]1O[C@H](COP(=O)(O)O)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C | 3943.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3745.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3279.0 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #8 | CC(C)(C)[Si](C)(C)N=C(CNC=O)N([C@@H]1O[C@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)[C@@H](O[Si](C)(C)C(C)(C)C)[C@H]1O)[Si](C)(C)C(C)(C)C | 3636.3 | Standard polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3819.9 | Semi standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3485.9 | Standard non polar | 33892256 |
| 5'-Phosphoribosyl-N-formylglycinamidine,5TBDMS,isomer #9 | CC(C)(C)[Si](C)(C)O[C@@H]1[C@@H](COP(=O)(O[Si](C)(C)C(C)(C)C)O[Si](C)(C)C(C)(C)C)O[C@@H](N(C(=N)CN(C=O)[Si](C)(C)C(C)(C)C)[Si](C)(C)C(C)(C)C)[C@@H]1O | 3737.2 | Standard polar | 33892256 |


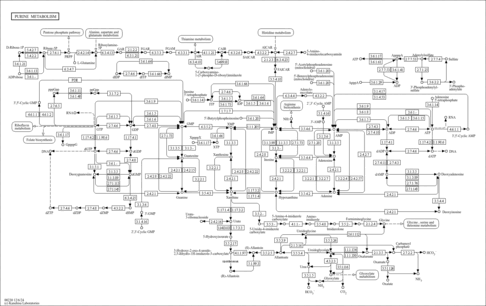
{kind=link}